In November 2022, Snowflake announced general availability of Python support for Snowpark (a set of libraries and runtimes that make it possible to execute non-SQL code in Snowflake). At the same time, strategic decisions were being made at Säästöpankki—the oldest commercial bank in Finland—regarding the development of data driven customer analytics solutions.
Snowpark was seen as a logical starting point, as the company had been investing in data warehousing in Snowflake for several years already. No additional technologies would be needed, which was seen as a clear benefit. This might sound like a leap of faith; early adoption can be rather risky. However, given the prior experience with Snowflake and the trust in the competence of the team, aligned with the future road map of Snowflake, the management was confident with the decision.
After a year of active development, trial and error, persistence, and good teamwork, more than ten use cases have been taken into production use. In the following, we will describe how this 200-year-old organization made this leap from zero to hero in predictive analytics.
Adopting a new technology is always time consuming. What helped a lot in case of Snowpark is that the Snowpark dataframe API—the main interface between Snowflake data and Python—closely resembles the Spark API for Python (pyspark). Spark has for long been, and still is, an important solution for handling big data ETL and ML workloads, which means that relevant coding skills are fairly easy to come by.
Well-designed is halfway done
Let’s start from the requirements; what is needed to set up a functional MLOps-pipeline? Essentially, we need good-quality (pseudonymized) data, reusable code, modularity, transparency, maintainability, model versioning, monitoring, and of course the deployment of models to production for generating predictions. Data governance and security is conveniently handled by the data platform (Snowflake).
To promote modularity, we have a dedicated analytics database in Snowflake, with several schemas (Fig. 1). Each schema has their own role in the pipeline. The first schema, ADM (Analytical Data Mart), contains views that standardize dimension and fact tables from the main data warehousing database. The unified structure of dimensions and facts facilitates programmatic feature and target engineering.
Having the ADM consist of views rather than tables liberates the MLOps pipeline from building automation for the data standardization. We only need to run the pipeline monthly, so the need to query the transformations every time is not an issue as there is no need to update the with a higher frequency. As a downside, pipeline steps using the ADM as a source (feature/target engineering) are relatively slow to execute.
The control of the workflow is written into configurations files. Basically, nothing has been hard coded into the python logic, which promotes reusability of the functionality. In order to execute the code in Snowflake, python functions are registered as Stored Procedures (SPROC) and the configuration files provide the required input arguments for each procedure. This allows us to quickly deploy workflow modifications to different environments (accounts/databases).
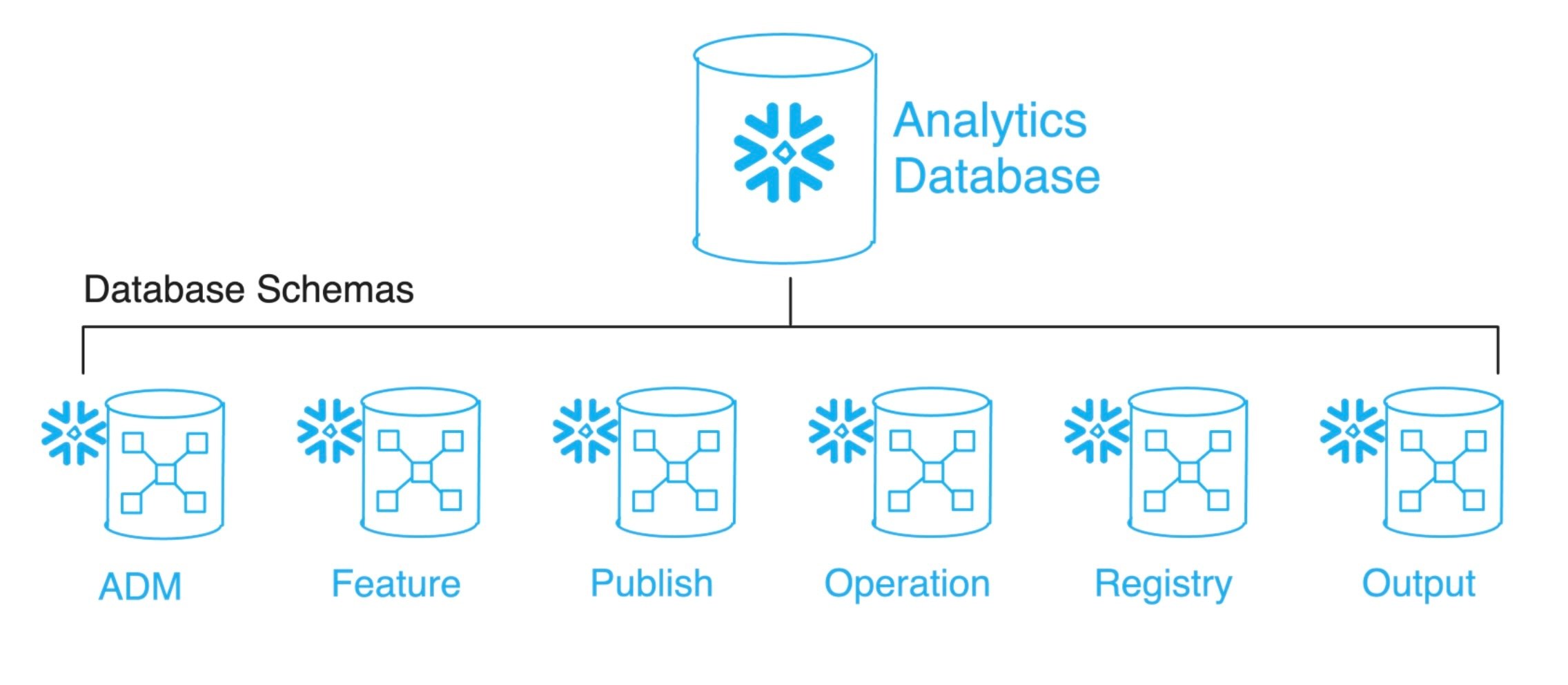 Fig 1. Modularity at the database level. Each schema has a different
Fig 1. Modularity at the database level. Each schema has a different
purpose in the MLOps workflow.
Refining raw data as fuel for (machine) learning
Data flow along the pipeline is handled using SPROCs (Fig. 2)—located in a dedicated schema (Operation Schema), which pack re-usable python code mainly written using the Snowpark dataframe API. The logic has been written in a way that adding new source data to, e.g., feature engineering requires no changes to the SPROC code (unless new feature types need to be introduced).
The resulting feature layer is a simple representation of a feature store, for which there are several open source and commercial solutions available. This tutorial shows how to use Feast with Snowflake. For now, the simple feature layer has been sufficient for our needs, but after a native Snowflake solution will enter public preview (later this year), we will consider adopting this feature. %20to%20traintest%20sets%20for%20modeling%20via%20data%20%20%20publishing%20and%20preprocessing%20is%20handled%20by%20Stored%20Procedures%20(SPROCs).jpg?width=2548&height=956&name=Data%20flow%20from%20standardized%20data%20(ADM)%20to%20traintest%20sets%20for%20modeling%20via%20data%20%20%20publishing%20and%20preprocessing%20is%20handled%20by%20Stored%20Procedures%20(SPROCs).jpg) Fig 2. Data flow from standardized data (ADM) to train/test sets for modeling via data
Fig 2. Data flow from standardized data (ADM) to train/test sets for modeling via data
publishing and preprocessing is handled by Stored Procedures (SPROCs).
The tables in the feature layer are joined to form a publish layer, which contains modeling (history) and scoring (production) data. This could be done separately for selected use cases, but we see no need for this and thus this layer is common for all downstream steps. The same goes for the preprocessing step, which uses sklearn/Snowpark-ML for building re-usable preprocessing transformer models, which are stored into Snowflake stage in a dedicated model-registry schema.
Preprocessing could also be done as a part of the model training (using sklearn/Snowpark-ML pipelines), but this would in our care bring unnecessary repetition of computation. In turn, the preprocessed modeling data is split into training and testing sets.
Data splitting can of course also be done ad hoc at model training. However, having a predefined testing set comes handy after model training when trained models are evaluated to decide which one will be used in production.
Robust production of fresh models for best insight
As with the preceding steps in the pipeline, one SPROC is used for model training irrespective of the use case. All behavioral changes required are handled by the input arguments. This has been done to maximize re-usability as well as to minimize maintenance requirements. The procedure logs the trained model to the Snowflake model registry (residing in a dedicated schema), where a new iteration of a given model name is stored as a new version (Fig 3.).
Following the model training, registered models are evaluated to decide which one will be used in production to generate predictions (Fig 3.). This can be done either by simply selecting the latest model, or by ranking the performance of a given set of model versions. In the latter case, all models are scored using the latest testing data and a suitable metric is used to tag the best one for production use.
Finally, the scoring procedure retrieves the production model for a given use case, calculates predictions for all targets for selected rows (customers) in the production data, and writes selected predictions to a dedicated table in the Output Schema (Fig 1.). Nothing special here.
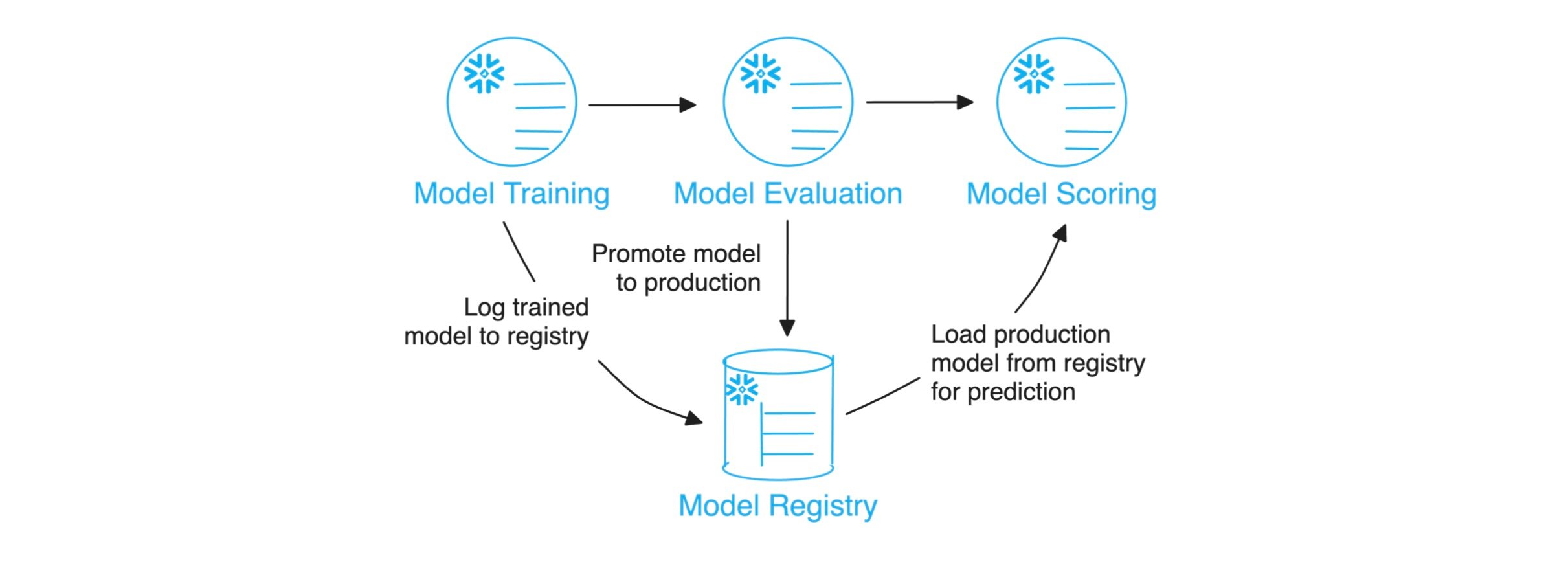 Fig 3. Model production pipeline, from training, via evaluation, to application.
Fig 3. Model production pipeline, from training, via evaluation, to application.
Orchestration is everything
A crucial element of an MLOps pipeline running in production is that it needs to operate automatically. When all the tasks have been registered as Stored Procedures, executing them is as simple as running an SQL query. This means that automatization can be achieved with any given orchestration tool. For simplicity, we have chosen to use Snowflake TASKs (Fig 4.).
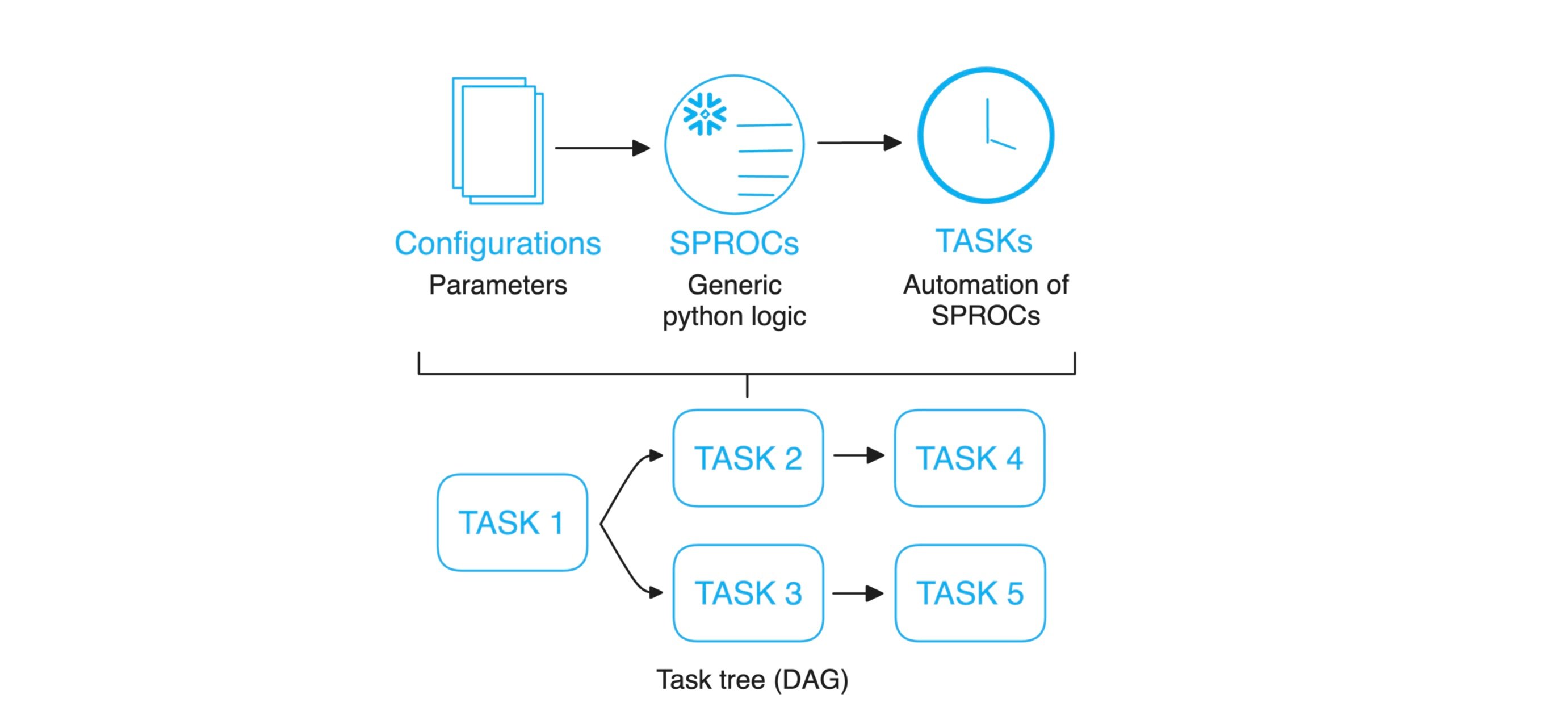
Fig 4. Reusable workflow automation.
A Snowflake task is a scheduled execution mechanism, enabling the automation of SQL queries and DML statements (such as INSERT, UPDATE, DELETE) as well as calling stored procedures. Importantly, Snowflake supports the creation of task trees (or DAGs, i.e., Directed Asyclic Graphs) by allowing tasks to have dependencies. A task can be configured to trigger other tasks upon successful completion, enabling complex workflows where the output of one task serves as the input for subsequent tasks.
As with SPROCs, definition of TASKs and DAGs is done with code, and thus the deployment of TASK pipelines can be generalised and parameterised. This means that existing pipelines can be updated and new ones deployed to any environment with identical code. This approach is simplistic, yet elegant, also promoting maintainability of the system.
Future steps
While Snowflake is doing massive development on MLOps capabilities of the platform, users have the liberty to design their MLOps framework as they please, with or without the native Snowflake features. For example, before the Snowflake Model Registry became a public feature, we were using mlflow for tracking model training and exporting the results to a database table.
The benefit of using native features is reduced complexity, but one is limited to those features available. However, the use of established third party solutions (such as mlflow) makes the code more portable between platforms. While there are no restrictions to available features, this adds a lot of complexity and makes maintenance much harder.
Monitoring plays a pivotal role in MLOps, but this feature is still missing from our framework. In general, monitoring is needed to identify model drift (i.e., models degrade in performance over time due to changes in underlying data patterns), data/feature drift (changes in feature distribution, missing values, or introduction of new categories), and concept drift (changes in the association between target variables and features).
Implementing effective monitoring involves selecting the right tools that offer detailed insights into model performance, data quality, and operational health. Additionally, integrating monitoring tools into the MLOps pipeline to automate responses, such as triggering model retraining workflows or alerting relevant teams, is key to maintaining a robust ML system.
It remains to be seen how well the upcoming Snowflake model monitoring feature as well as Snowflake Feature Store will meet these needs. Still, we always have the option to complement our framework with third party solutions.
Summary
The Snowflake/Snowpark platform offers a streamlined and efficient architecture for MLOps development and automation, addressing the challenges of managing machine learning lifecycles in a cloud environment. By leveraging Snowflake's cloud data platform capabilities alongside Snowpark's developer framework, we get a simplified and accelerated experience of the deployment and management of machine learning models and associated data pipelines.
Snowflake simplifies data management, as the cloud-native architecture centralizes data storage, processing, and analysis. This unified data repository simplifies data access, querying, and preparation tasks, crucial for feeding high-quality, consistent data into machine learning models. The ability to scale compute resources up or down based on workload requirements supports efficient MLOps practices by optimizing performance and cost.
The Snowpark DataFrame API allows developers to execute Scala, Java, and Python code directly within Snowflake. This integration enables the development and execution of machine learning models within the Snowflake environment, reducing the complexity and latency associated with moving data between systems. Stored procedures (and user defined function) further enhances the capability to embed complex data transformations and machine learning inference logic close to the data.
Snowflake also facilitates collaboration between data engineers, data scientists, and ML engineers by providing a common environment for data processing and model development. This collaborative approach ensures alignment on data definitions, model inputs, and business objectives.
While Snowflake itself does not directly offer specialized MLOps tools for model monitoring and automation (yet), its ecosystem and integration capabilities with external tools and platforms enable robust MLOps workflows. For example, data pipelines can be automated using Snowflake tasks and external orchestration tools like Apache Airflow, while model performance and data drift can be monitored using custom queries and dashboards or integrated third-party monitoring solutions.
In conclusion, the Snowflake/Snowpark platform provides a powerful, lightweight architecture for MLOps by offering scalable compute resources, simplified data management, and an integrated development environment. This enables organizations to develop, deploy, and manage machine learning models more efficiently, with the added benefits of enhanced collaboration, security, and compliance. While certain aspects of the full MLOps lifecycle may require integration with external tools, Snowflake/Snowpark lays a solid foundation for building and automating machine learning operations.
All figures were created using https://excalidraw.com/.
Photo by Marek Piwnicki on Unsplash
Lasse Ruokolainen-Pursiainen, Principal Data Scientist, Kaito Insight Oy
Jarkko Utter, Senior Data Analyst, Säästöpankki


