It goes without saying that the amount of data being gathered just keeps increasing, together with the methods and tools we use to gather it. The more data is being gathered the more people there are accessing it, which means that the various demands from the people around the data also increases.
Looking on a high-level at a particular AWS technology called AWS Glue, which is a fully managed serverless ETL (extract, transform and load) service, which requires no infrastructure nor a separate setup. The basic ideology behind AWS Glue is that you can point any data source/data store in AWS to AWS Glue which then stores the data with the defined metadata into a catalog. From this catalog you have complete access to all the data stored in it.
Building a data lake with analytics using AWS Glue and Crawlers
With AWS Glue you have several useful functions ready to be used, and one is AWS Crawlers. Crawlers are basically the primary tool for building the catalog, since it can read both structured and unstructured data and prepares and stores the metadata for AWS Glue and also enables the use/read of several s3 database tables.
 Picture taken from: https://aws.amazon.com/glue
Picture taken from: https://aws.amazon.com/glue
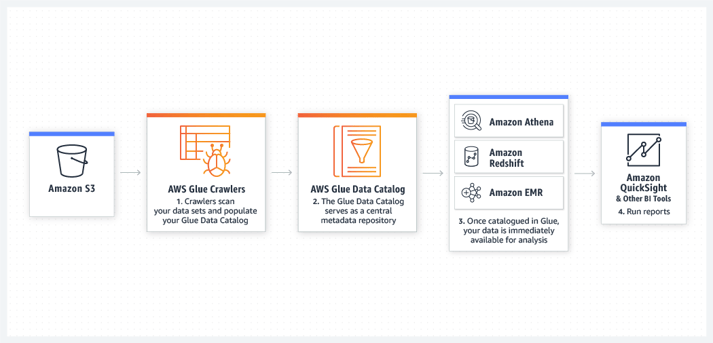
A quick use case would be using AWS Glue for building a data lake and placing analytics capabilities into it. The process is simply using AWS crawlers to build metadata from an S3 bucket datasets, prepare a data catalog and push it into a data warehouse and connect any BI reporting tools your company may have.
This is a very efficient and powerful way of analyzing data, and also as a use case it is simple enough to provide the ideology and capabilities of AWS Glue catalog and AWS Crawlers. Perhaps in the next blog we could have a quick look how to build a serverless data pipeline analytics by using AWS Glue Catalog.



